WAFR2020: The Surprising Effectiveness of Linear Models for Visual Foresight in Object Pile Manipulation
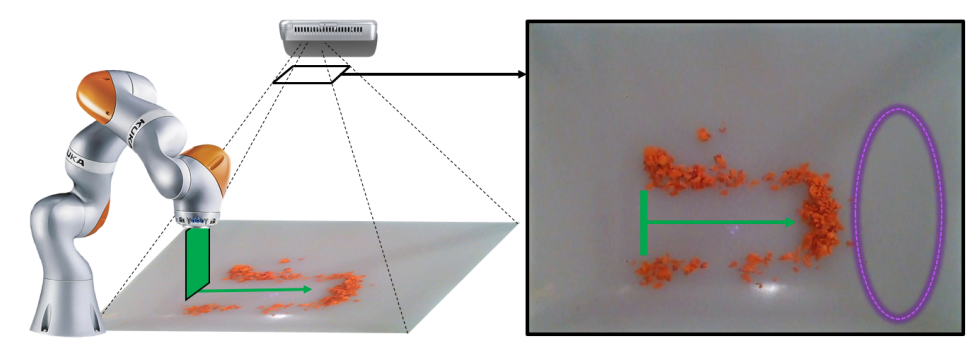
Table of Contents
Abtract
本文1发表于WAFR 2020。该论文研究了基于模型的物体堆操作策略(如一堆切好的胡萝卜)。该论文使用了三种方法对物体堆的动力学进行建模:1.线性模型;2.深度自编码器模型;3.面向物体的动力学模型。实验结果表明,深度自编码器模型的泛化能力在该任务上是最差的。其余两个模型都有较好的泛化能力,能够在真实场景的任务中取得较好的性能,而线性模型在三种模型中表现是最好的。
Discussion
具体算法细节和实验结果可参考原文。这里总结一些这篇文章中值得思考的点:
1.为什么1M参数的线性模型在1K数据上训练后,在三种模型中表现最好?而2M参数的DVF在23K数据上过拟合?
众所周知,线性模型可以作为一种最简单的深度模型。 其形式简单,参数少,对于特定数据集有最优的解析解。 但是其作为最简单的深度模型(也即仅有一层的不包含激活函数的全连接网络),在只有1000数据的情况下(1M参数)仍然表现出比在23K数据下训练的深度模型(2M参数)更好的泛化能力。 总结可能的原因如下:
1)结构先验:文章中任务的dynamics较为简单(从object-centric dynamics即可解决问题可以看出),因此线性模型的归纳偏置可能比CNN小。
2)全局最优:线性模型可以解得全局最优解,而CNN只能通过梯度下降优化,因此会收敛至局部最优解。
3)输入维度:与DVF-Original相比,线性模型的输入不包含a,这减小了输入空间,使得学习更加简单。
一个更深层次的问题:在什么任务上线性模型能够取得更好的性能?什么时候需要用深度学习,什么时候需要用线性回归? 基于这篇文章的任务,关于使用线性回归性能较好的原因,初步的结论包括:
1)简单的状态表征(当前图像减背景后非零值点较少)。
2)简单的动力学模型(仅有推动的动作,因此大部分的非零像素点都不会有较大移动)。
3)能够对输入进行简化。 如本文中对动力学输入解耦,将易于使用解析方法处理的部分独立出来(如文章中所用的通过仿射变换减小动作空间的方法),仅对不易于使用解析方法处理的部分进行学习,以减小学习难度。
2.在该任务中,为什么使用贪婪策略而非规划算法?
本文虽然是基于模型的控制,但却并不涉及长时规划算法。 可以看到,即使在最复杂的任务设置下,使用单步的贪婪搜索策略也能取得较好的性能。 因此对于较为简单的任务,规划算法并不能够带来足够的性能提升。 相反,对于这种任务较简单,动力学模型缺并不精确的任务,使用长时规划甚至有可能出现性能的退化。 原因在于长时规划所获取的最优动作,往往建立在对未来状态的准确估计上。
所以规划算法并不总是有效,规划算法往往运用在简单动力学模型+复杂策略的任务中。 而对于文中所示的复杂动力学模型+简单策略,则不太适用。 进而,对于更复杂任务(复杂动力学模型+复杂策略),往往需要结合学习和规划的优势。
3.DVF-Origin和DVF-Affine的对比似乎说明了深度学习并不适合学习形如s’=f(s,a)的动力学模型。那么在学习动力学模型的过程中,文章的解决思路有什么启发?
文章中DVF-Origin和DVF-Affine的对比说明了深度学习似乎并不适合学习形如s’=f(s,a)的动力学模型。 相反,对于离散的动作空间,通过单独的学习不同动作对应的动力学模型会取得更好的性能。 可能的原因在于如果将动作a作为输入送入网络进行训练,那么在测试过程中所出现的未知动作会导致模型产生不可预测的错误输出(即加剧了模型的Out of distribution, OOD问题)。 如在推碎萝卜的任务中,如果对于某个未知动作a,深度学习获取的动力学模型判断a是一个最优动作,但a并未与物体堆接触,那么很有可能会造成所学策略在测试时陷入死循环,从而造成任务失败。
对于该问题,可能的解决思路包括:
1)使用更多的训练数据。
2)降维输入空间(状态动作的联合空间),如解耦出可用解析方法建模的分量。
3)引入结构先验。如在设计网络结构包括输入输出时,应充分考虑实际的物理性质。
REFERENCES
-
Suh, H. J., and Russ Tedrake. “The surprising effectiveness of linear models for visual foresight in object pile manipulation.” arXiv preprint arXiv:2002.09093 (2020). ↩